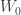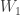Intro
確率的勾配降下法のサンプルをネットで調べていたところ、検索結果のトップ群にQiitaの記事になかなか収束しないという話があったが、もろもろ調べて考察した結果、事前処理としてデータの正規化をすれば収束性が改善するらしい。ここでは事前処理のありなしで収束性がどう変わるか比較する。
Wikipediaの確率的勾配降下法のページの平均・分散の調整セクションに、”訓練データの正規化をして、平均0分散1になるように調整する方が良い”とある。これは、あまりにも大きさの異なるデータがあるとコスト関数の形状が潰れてしまい収束性が悪くなってしまうため、整形する目的で訓練データを定数で加減乗除して収束性の改善を図る。この定数に平均や分散を使う。
問題設定・正規化前の学習則
Qiitaの記事と問題設定を揃える。訓練データの数を


![w = [w_0 , w_1]](https://s0.wp.com/latex.php?latex=w+%3D+%5Bw_0+%2C+w_1%5D&bg=ffffff&fg=333333&s=0&c=20201002)



もう少し詳しく書くと

この
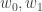


学習率を


正規化後の訓練データによる学習
訓練データ集合




このデータ集合を訓練データとして、別の線形回帰モデル
![W=[W_0, W_1]^T](https://s0.wp.com/latex.php?latex=W%3D%5BW_0%2C+W_1%5D%5ET&bg=ffffff&fg=333333&s=0&c=20201002)



すなわち





学習率を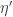


正規化後のモデルパラメータから正規化前への変換
正規化前後のパラメータ




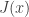




もとの線形回帰モデル


が得られる。上2式を


すなわち

が求まる。
訓練データの生成と正規化
訓練データは以下の式で生成する。





ただし上述の正規化のための線形変換には






としてQiitaの訓練データ集合を似せた結果がこちら。左が生成したデータ、右が生成したデータに線形変換をして正規化したデータ。正規化後はゼロ付近に分散されている。

コスト関数は以下のように変わる。左が正規化前、右が正規化後のコスト関数。このコスト関数が最小になるように、凹地の底へ行くように

学習結果
初期パラメータを

 下図は横軸を反復回数の対数をとって、縦軸を正規化前の履歴と、正規化後から変換した履歴。下図中の左上がコスト関数の履歴、左下が
下図は横軸を反復回数の対数をとって、縦軸を正規化前の履歴と、正規化後から変換した履歴。下図中の左上がコスト関数の履歴、左下が
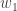
一方で、正規化後のコスト関数は収束が遅くなっているが、訓練データによる学習が一巡する1,000回あたりで変動は小さく安定して収束している。正規化後の
両者ともコスト関数の最小値は同じ値を示しており、パラメータの履歴と同じく、真値付近でウロウロしているのがここでも読み取れる。また、コスト関数は
 おまけ、正規化後の履歴。同様に左上がコスト関数の履歴、左下が
おまけ、正規化後の履歴。同様に左上がコスト関数の履歴、左下が